
NLP大模型缺席,不赶“热点”只谈应用的华为,功夫在“山外”。
在沉寂两年后,华为云官网近期上线了盘古系列AI大模型的最新消息,同时,华为云人工智能领域首席科学家田奇于今日在人工智能大模型技术高峰论坛上介绍了盘古系列大模型的进展及其应用,一时拉高了人们对这次演讲的期待值。
恰是阿里云“通义千问”大模型公布的第二天,一时间业界也有“华为加入大模型之争”的猜测。有了期待值和预期,田奇今日的演讲是否满足了观众的好奇心呢?我们接下来会在文章中回顾华为盘古大模型的前世今生,以及华为在将盘古大模型推向公众视野的演讲中透露了哪些进展。
NLP大模型缺席,何时揭开面纱成谜
盘古大模型的历史至今也才三年时间。2020年11月,盘古大模型在华为云内部立项成功,该模型也完成了与合作伙伴、高校的合作搭建。在开始打造盘古大模型的时候,华为内部团队确立了三项最关键的核心设计原则:一是模型要大,可以吸收海量数据;二是网络结构要强,能够真正发挥出模型的性能;三是要具有优秀的泛化能力,可以真正落地到各行各业的工作场景。2021年4月,盘古大模型正式对外发布。
华为云官网更新的最新消息显示,华为即将上线的“盘古系列AI大模型”分别为NLP 大模型、CV大模型、科学计算大模型(气象大模型)。国盛证券近期发布的研报中表示,盘古 NLP 大模型是业界首个千亿参数的中文预训练大模型;盘古CV大模型是业界最大 CV 大模型、首次实现兼顾判别与生成能力、在 ImageNet 上小样本学习能力上处于业界第一;盘古气象大模型则可提供秒级天气预报,可应用于气象、生物医药等领域。
但在会上,田奇对于NLP大模型仅用一句话带过其应用进展,他表示盘古NLP大模型目前覆盖的智能文档检索、智能 ERP、小语种大模型等落地领域,2022年华为刚交付了一个阿拉伯语的千亿参数大模型。半小时的演讲听下来像做了一套盘古大模型的面试介绍或者入职第一个月的职业规划,让人感觉“能摸到头脑,但是不多”。有网友对没有盘古大模型的演示表达了强烈的不满,但既然演讲中NLP大模型并非主角,那行业大模型当场演示确实有些强人所难。也有网友吐槽“都是些之前老的to B的东西重新拿出来简单介绍了一下”。
作为盘古系列大模型中最受关注的大模型,与ChatGPT等外国同类AI模型相比,盘古NLP大模型更注重针对中文语言的优化,该模型采用了深度学习和自然语言处理技术,并使用了大量的中文语料库进行训练。在应用方面,盘古大模型可以应用于智能客服、机器翻译、语音识别等多个领域,提供AI技术支持。
从参数与数据堆量来看,百度大模型的参数为100亿,而GPT-3达到了1750亿,GPT-4尚不明确。根据前段时间华为发表的论文数据判断,华为PanGu-Σ大模型参数最多为1.085万亿,基于华为自研的MindSpore框架开发。PanGu-Σ大模型在对话方面,回答更贴近主题,也更准确。在参数角度,盘古大模型可能已经接近 GPT-3.5 的水平。

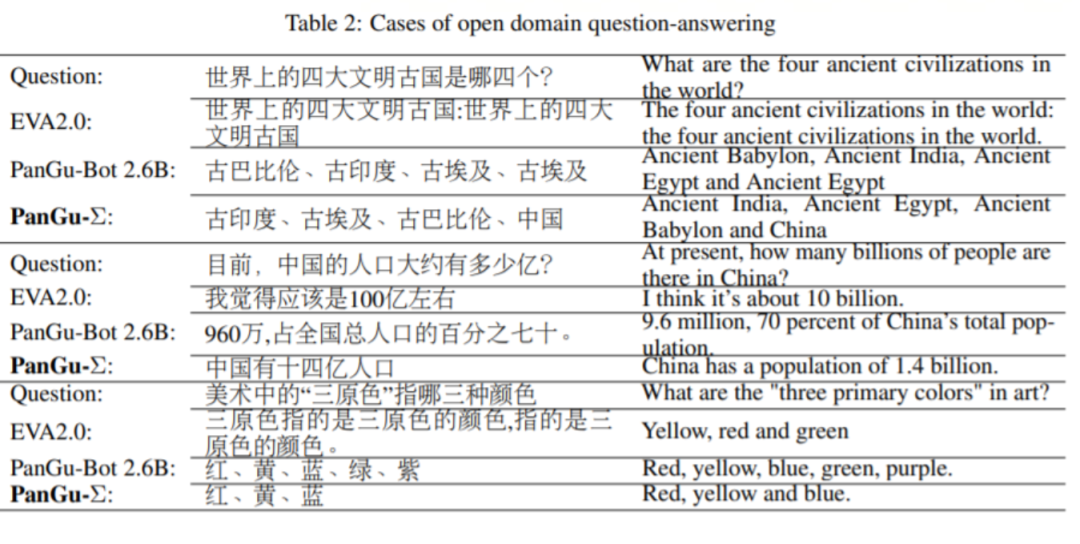
图源:《PANGU-Σ: TOWARDS TRILLION PARAMETER LANGUAGE MODEL WITH SPARSE HETEROGENEOUS COMPUTING》
与其他厂商相比,华为的优势或在于拥有完整的产业链和较强的算力调配能力。据介绍,在训练千亿参数的盘古大模型时,华为团队调用了超过2000块的昇腾910,进行了超过2个月的训练。
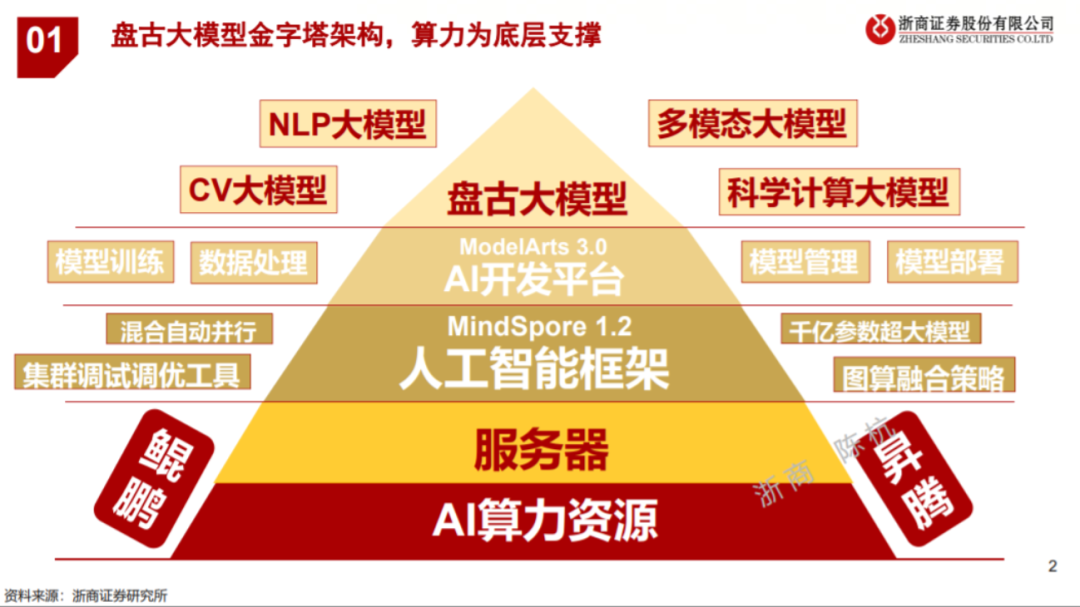
图源:《华为AI盘古大模型研究框架》,浙商证券
瞄准行业赋能,华为大模型坚定“AI for Industries”
目前,全球人工智能产业正处在AI工业化开发模式起步后的快速发展阶段,而大模型是最有希望将AI进行落地的方向。大模型最重要的优势是推动AI进入大规模可复制的产业落地阶段,仅需零样本、小样本的学习就可以达到很好的效果,以此大大降低AI开发成本。
华为从2020年就关注到了人工智能技术的两大落地趋势:
一、从小模型到大模型演进。过去十年内,AI算法的算力需求提升了40万倍。大模型将成为应对 AI 应用碎片化的一种方式,因为存在较高的资金门槛和技术门槛,可能存在大公司收编高度定制化的小模型的现象,导致市场向大公司集中,产业规则和格局也可能改变。
二、AI for science,AI与传统科学计算领域渗透融合,将会为包括传统的气象、海洋、农业、地球科学、航空航天等领域贡献从偏微分方程的方法拓展到 AI 方法,在这一领域华为云推出了气象、药物分子领域的多个行业大模型。
华为盘古大模型基于底层一站式 AI 开发平台 ModelArts 建立了L0基础大模型、L1行业大模型、L2场景模型多层服务。具体而言,基础通用模型L0与行业的海量数据混合训练得到行业模型L1,将L1部署到产业下游千行百业的细分领域中,得到细分场景模型L2。为了降低生产成本,提高效率,尽快为行业赋能,华为过去几年主要在做盘古系列与训练大模型。

据田奇介绍,华为云过去几年实践的人工智能项目已经超过1000个,其中30%人工智能项目已经进入了核心生产系统,帮助客户将盈利能力平均提升18%。他预测,人工智能行业渗透率将再度提速,在2026年对企业的渗透率将达到20%。
自华为2021年开始立项盘古大模型以来进展不断——2021年4月发布了盘古NLP大模型、盘古视觉大模型、盘古科学计算大模型;2021年9月,推出用于药物研发细分场景的大模型;2022年,其与能源集团合作发布了盘古矿山大模型、盘古气象大模型、盘古海浪大模型、盘古金融OCR大模型。
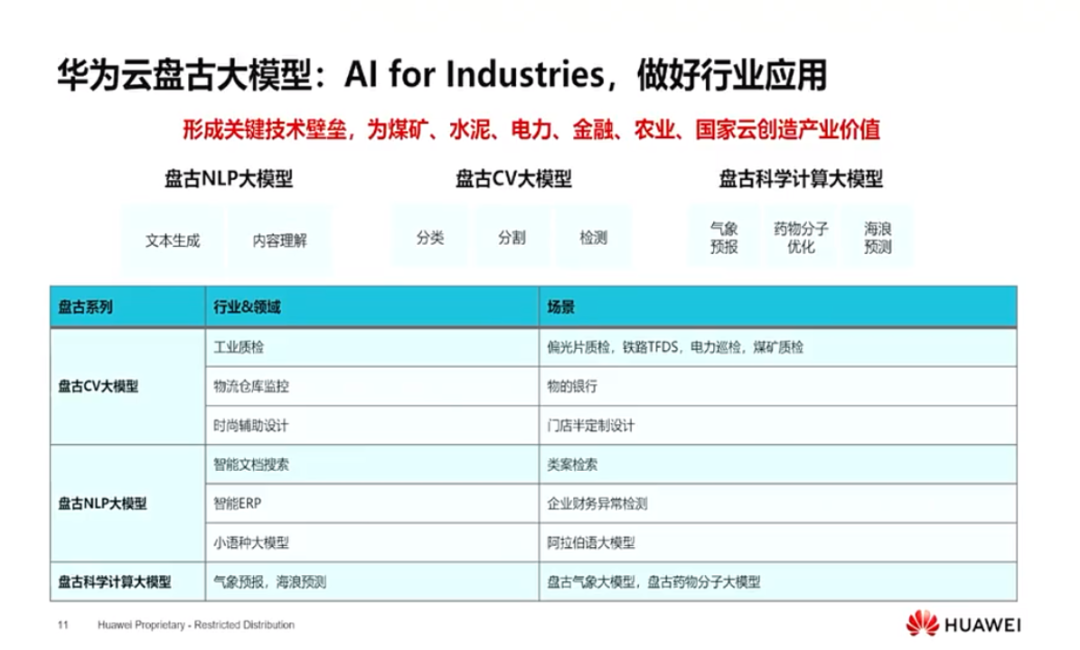
田奇表示,2022年,华为盘古大模型主要在做 AI for Industry(AI 赋能产业),例如视觉大模型已经在工业质检、缺陷检测、电力巡检等100多个场景得到验证。华为大模型产业化的初衷在于开辟更多B端业务场景,正如田奇此前所说,“将工业化的一面放置在更高的优先级上”。华为希望通过盘古大模型为煤矿、水泥、电力、金融、农业等行业创造更多产业价值。
田奇还表示,大模型是连接技术生态和商业生态的桥梁,是未来AI生态的核心。华为云盘古大模型能够推动人工智能开发从“作坊式”到“工业化”升级。展望未来,AI for Industries是人工智能新的爆发点。盘古大模型将解决传统AI开发的难题,包括作坊式开发、样本标注、代价大、模型维护困难、模型泛化不足、行业人短缺等难题等。
田奇着重介绍了盘古大模型中CV大模型和的落地情况,具体如下:
CV大模型
在与能源公司合作的盘古矿山大模型中案例中,矿井现场是一个 40 米长的采掘机,宽度仅 2 米左右,传统相机很难一下子捕捉到全部画面,只能用图中的九宫格视频画面。通过 5G+AI 全景视频拼接综采画面卷,传输到地面,地面工作人员将来可以实现地面控制机器进行采矿,实现矿下无人少人安全作业。
盘古矿山大模型还用在了煤矿的主运输皮带作业监控。煤矿被采集下来以后,它会通过一个主运输皮带,从地下传输到地上。按传统方法是通过工人配合作业。华为提出通过视频对作业的安全规范进行巡检,主运场景的异物识别精度达 98%,煤矿作业场景动作识别准确率达 95%,助井下安全事故减少 90% 以上;此外大模型还能进行轨道机车缺陷检测,比如掉链、脱落、裂痕等潜在不安全因素,人工检测成本较高,盘古大模型提供图像质量的自动评估、小样本的故障定位与识别等。


科学计算大模型
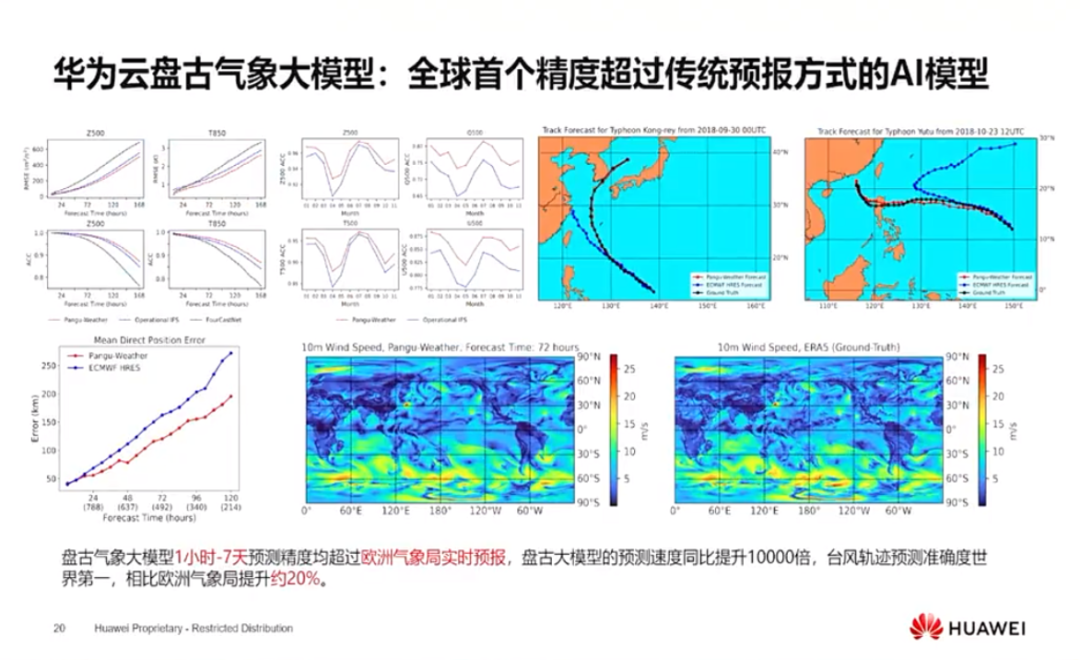
华为云盘古科学计算大模型加速了人工智能在科学计算方面对于模型、算法、软件、硬件四个方面进行融合。该模型是全球首个精度超过传统预报方式的AI模型,可以在秒级的时间内完成全球未来全球一个小时到七天的全球天气预报,其精度首次超过了欧洲气象中心的数值分析方法,并且预测速度相对于传统的数字分析方法提升了1万倍以上。此外,华为云盘古药物分子大模型缩短先导药物研发周期从数年到1个月。


中国大模型竞争在所难免
关注股市的读者朋友今年基本都会对ChatGPT概念股倾注一些关注,而此类炒作中,我们已经见证过不少速生速死的案例。在关注此方面上市公司近期动态时,我们发现不少公司发出了“AIGC、大模型、人工智能相关产品并未对公司产生任何收入”的声音。将目光从资本市场转移到实际应用上,AI真正在产业侧掀起“ChatGPT式”的大变革似乎还很遥远。在C端市场的传播度与基本声量,是B端市场所不能及的;但B端市场能够给予的资金底座和长线收益,也是高速变动的C端市场可望不可及的。
任何一门技术突破都需要以产业赋能为技术指引,对于大模型而言,如果在NLP方面丧失先机,处在追赶国外的境况,不妨直接从产业侧出发,依托中国本身具备的庞大业态寻求突围机会。在此方面,正如田奇所言,大小模型协同进化将成为行业趋势,共同推动端侧化发展。
如果将ChatGPT的成功模式复用到B端,以轻量化服务降低应用门槛一定是一条重要路径。大模型具有良好的通用性、泛化性,能够显著降低人工智能应用门槛。预训练大模型在海量数据的学习训练后具有良好的通用性和泛化性,用户基于大模型通过零样本、小样本学习即可获得领先的效果,同时“预训练+精调”等开发范式,能够让研发过程更加标准化,这将降低人工智能的应用门槛,也将是AI走向工程化应用落地的重要手段。
在过去在分散化的模型研发模式下,单一的AI应用场景下的多个任务都需要由多个模型支撑完成,每一个模型建设都需要算法开发、数据处理、模型训练与调优过程。预训练大模型增强了人工智能的通用性、泛化性,基于大模型通过零样本或小样本精调,就可实现在多种任务上的较好效果。大模型“预训练+精调”等模式带来了新的标准化AI研发范式,实现AI模型在更统一、简单的方式下规模化生产。
随后,大模型负责向小模型输出模型能力,小模型更精确地处理自己“擅长”的任务,再将应用中的数据与结果反哺给大模型,让大模型持续迭代更新,形成大小模型协同应用模式,达到降低能耗、提高整体模型精度的效果。
据IDC预测,未来大模型将带动新的产业和服务应用范式,在深度学习平台的支撑下将成为产业智能化基座,企业需加快建设人工智能统一底座,融合专家知识图谱,打造可面向跨场景或行业服务的 “元能力引擎” 。
从近期的行业乱战来看,中国企业不擅长做“有趣的技术”,但执着于行业首创的“模式”。追逐浪潮在所难免,但相较于大语言模型,我国大厂在几年前就纷纷推出行业大模型,在此方面存在一定的先行布局,此方面一定需要继续加码,但在大语言模型方面,中国需要几个“轮子”目前还没有定论,这等耗时耗力的活计,唯有留给一线的大厂来思考。
参考资料:
1.《华为盘古大模型新进展,华为云 AI 首席科学家 7000 字演讲精华》,智东西
2.《华为AI盘古大模型研究框架》,浙商证券
3.《2022中国大模型发展白皮书》,IDC
